Delta Channels: 장시간 실행되는 에이전트를 위한 런타임 진화 방식
TMThttps://www.langchain.com/blog/delta-channels-evolving-agent-runtime
핵심 요약
- 기본 전체 스냅샷 방식에서는 체크포인트 저장소가 O(N²)로 증가합니다. 메시지 히스토리가 길고, 파일시스템 기반 컨텍스트를 많이 쓰는 에이전트일수록 운영 비용이 빠르게 커집니다.
- DeltaChannel은 각 스텝마다 변경분(delta)만 저장하고, K 스텝마다 전체 스냅샷을 쓰는 방식으로, 재개(resume) 지연 시간을 일정 수준으로 묶어 두면서 세션이 길어져도 저장 비용을 사실상 일정하게 유지합니다.
- 업그레이드는 투명하게 적용됩니다. 기존 스레드는 그대로 동작하고, Deep Agents v0.6에서는 messages와 files가 기본적으로 delta 기반으로 동작합니다. LangGraph API 전체 표면(인터럽트, 타임 트래블, 툴링)은 그대로 유지됩니다.
Deep Agents는 LangGraph 런타임 위에 구축되어 있으며, 에이전트가 한 스텝 진행할 때마다 체크포인트를 남깁니다. 이 덕분에 관측 가능성, 인간 개입(human-in-the-loop), 장애 복구가 가능해집니다. 에이전트가 지금 어디까지 와 있는지 항상 정확히 알 수 있고, 어느 지점에서든 다시 이어서 실행할 수 있습니다.
에이전트의 성능이 좋아질수록 다음과 같은 일이 벌어집니다.
- 더 오래 실행되면서, 메시지 히스토리가 수십·수백 스텝에 걸쳐 길어집니다.
- 더 많은 컨텍스트를 사용하게 되며, 컨텍스트 관리와 오프로딩을 위해 파일시스템을 적극적으로 활용하게 됩니다.
Deep Agents에서는 메시지 히스토리와 파일이 에이전트 상태(state)에 포함됩니다. 그리고 매 스텝마다 스냅샷을 찍는 방식에서는 체크포인트 저장소가 **O(N²)**로 불어납니다. 200턴 동안 실행되는 코딩 에이전트의 경우, 기존 체크포인트 방식은 체크포인터에 5.3GB를 직렬화합니다. Delta 채널을 쓰면 이 용량이 129MB로 줄어들어, 40배 이상 절감되면서도 상태 복원(rehydration) 성능 저하는 사실상 없습니다.
Delta 채널은 이런 요구에 맞추기 위해 런타임을 발전시키는 핵심 수단입니다. DeltaChannel은 langgraph 1.2에 새로 도입된 프리미티브로, 누적되는 상태 필드의 체크포인트 방식 자체를 바꿉니다. 매 스텝마다 전체 스냅샷을 직렬화하는 대신, 그 스텝에서 새로 추가된 변경분만 저장합니다. 전체 스냅샷은 주기적으로만 기록해, 복구 비용이 일정 수준을 넘지 않도록 유지합니다. Deep Agents에서는 messages와 files가 이런 delta 기반 저장 방식을 사용합니다. 에이전트의 전체 진행 히스토리를 그대로 보존하면서도, 그 비용은 극적으로 줄어듭니다.
LangGraph에서 체크포인트 저장소는, 메시지 히스토리가 긴 에이전트의 경우 O(N²)로 증가합니다. 200턴 동안 실행되는 코딩 에이전트라면, 이 용량이 5.3GB에 이릅니다. Delta 채널을 사용하면 이를 129MB까지 줄일 수 있어, 아무 추가 작업 없이도 41배 절감 효과를 얻습니다.
문제: O(N²) 체크포인트 저장소
기본 LangGraph 체크포인트 모델은 매 스텝마다 에이전트 상태 전체의 스냅샷을 씁니다. 작고 짧게 실행되는 에이전트에겐 이 방식으로 충분합니다. 하지만 messages와 files는 _append-only accumulator_입니다. 즉, 한 번 추가된 내용은 사라지지 않고 계속 뒤에 붙기만 합니다.
전체 스냅샷 방식을 쓰면, N번째 체크포인트에는 1번부터 N번 스텝까지의 모든 내용이 들어가게 됩니다.
이렇게 되면 체크포인트 레이어 전체에서 성장 속도가 기하급수적으로 커집니다. 스텝이 하나 진행될수록 직렬화해야 할 데이터는 늘어나고, 체크포인터에 써야 할 blob도 커지고, 이를 메모리에 유지하는 비용도 커집니다. 결과적으로 직렬화 시간, write 증폭, 중복 저장이라는 세 가지 비용을 모두 치르게 됩니다.
해결책: Delta 채널
채널(Channels)은 LangGraph에서 그래프 상태의 “필드”를 표현하는 기본 단위입니다. 어떤 채널 타입을 쓰느냐에 따라 체크포인트 사이를 오가는 데이터 방식이 달라집니다.
DeltaChannel은 LangGraph 1.2(현재 베타)에 새로 추가된 채널 타입으로, 누적되는 필드의 체크포인트 표현 방식을 바꿉니다.
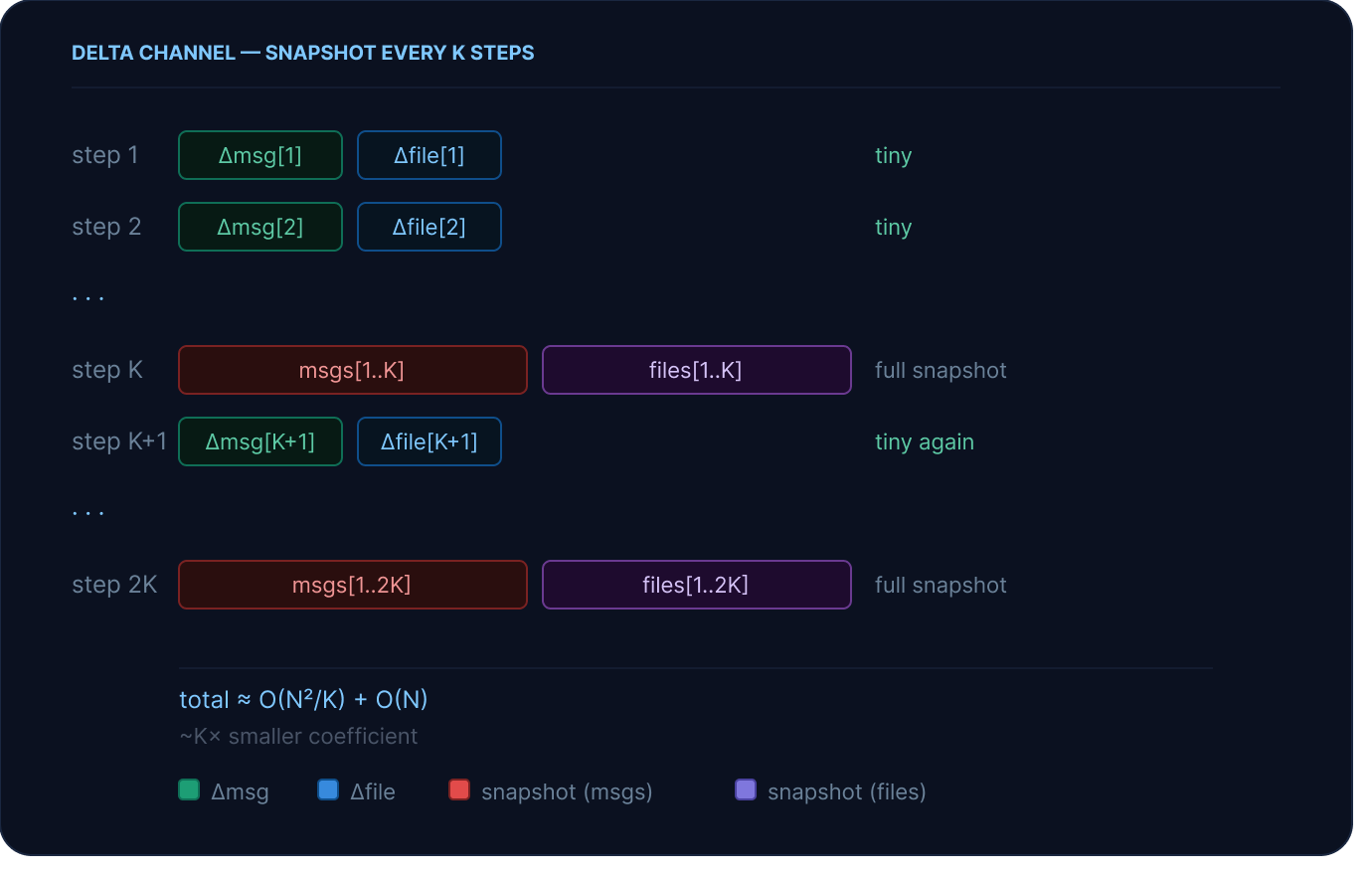
일반적인 스텝에서는 DeltaChannel이 그 스텝에서 새로 추가된 변경분만 아주 작은 delta 형태로 기록합니다.
그리고 snapshot_frequency=K 스텝마다 전체 스냅샷을 한 번씩 기록합니다( deepagents 의 기본값: 50). 이 설정은 재시작(resume) 시 상태를 복구하는 비용의 상한을 정해 줍니다. 세션을 처음부터 끝까지 모든 delta를 재생(replay)해야 하는 대신, 런타임은 가장 가까운 전체 스냅샷까지 거슬러 올라간 뒤, 최대 K 스텝만 재생하면 됩니다. 이런 주기적인 스냅샷이 없다면, 세션이 길어질수록 재개 시간이 선형적으로 길어지게 됩니다.
{kind=link}
엄밀히 말하면, 스냅샷을 K 스텝마다 찍기 때문에 이 방식에서도 성장률 자체는 여전히 O(N²)입니다. 다만, 그 계수(coefficient)가 기존 대비 대략 ~1/K 수준으로 줄어듭니다. 실제 세션 길이 범위에서는 O(N) 수준의 delta 항이 더 지배적이고, 복구 비용은 K에 의해 상한이 정해지므로 재개 지연 시간은 거의 일정하게 유지됩니다. 저장 효율 개선은 사실상 공짜에 가깝습니다.
표준 스냅샷 방식과 delta 방식의 동작을 나란히 비교한 개념도입니다.
벤치마크 결과
DeltaChannel은 LangGraph의 기본 프리미티브이지만, 이를 도입하게 된 실제 계기는 Deep Agents의 코딩 세션 워크로드였고, 여기서도 그 성능을 집중적으로 측정했습니다. 긴 메시지 히스토리와 파일시스템 기반 컨텍스트 오프로딩이 바로 O(N²) 체크포인트 증가가 실질적인 운영 문제로 부각되는 상태 형태입니다.
이번에는 두 가지 워크로드를 구성해 테스트했습니다.
| 항목 | 워크로드 A: 경량 코딩 / 검색 에이전트 | 워크로드 B: 다중 파일 기능 구현 |
|---|---|---|
| 시나리오 | 가벼운 코딩 / 검색 에이전트 | 여러 파일 기능 구현 |
| 턴당 파일 쓰기량 | 1 × 1 KB | 2 × 8 KB |
| 턴당 검색 결과 크기 | 1 × 1 KB | 1 × 5 KB |
| 대용량 검색 결과 | 10턴마다 82 KB | 5턴마다 100 KB |
| 턴당 AI 응답 | 최소 수준 | 약 200 토큰 |
주기적으로 발생하는 대형 검색 결과는 FilesystemMiddleware의 20k 토큰 축출(eviction) 임계값을 초과해, messages에서 files로 오프로딩됩니다.
방법론
모든 벤치마크는 완전히 모킹된 워크로드를 사용했습니다. 즉, 실제 LLM 호출은 없고, InMemorySaver, 결정론적(mock) 모델만 사용해 완전히 재현 가능한 환경을 만들었습니다. 표에 기재된 수치는 세션 전체에서 체크포인터에 누적된 총 체크포인트 저장 용량입니다. 토큰 카운트는 FilesystemMiddleware가 내부적으로 축출 임계값 계산에 사용하는 total_message_chars / 4 근사치를 그대로 사용했습니다.
셋업은 다음과 같습니다.
checkpointer = InMemorySaver()
agent = create_deep_agent(
model=_MockModel(), # deterministic mock, no API calls
tools=[external_search],
checkpointer=checkpointer,
)
for i in range(turns):
agent.invoke({"messages": [HumanMessage(...)]}, config)워크로드 A: 가벼운 코딩 및 검색
저장소 사용량은 초반에는 완만하게 증가하다가, 전체 스냅샷 크기가 커질수록 기하급수적으로 가속합니다. 500턴 시점에 기준 방식은 누적 4GB에 도달하지만, delta 채널을 사용하면 110MB 아래로 억제됩니다.
절감 비율은 10턴에서 6배 수준으로 시작해, 500턴 시점에는 41배까지 올라갑니다. 이 수치는 계속 증가하긴 하지만, 이론적인 상한치인 약 ~K배에 점점 가까워지면서 증가 속도는 둔화됩니다. 이 상한은 고정값이 아니며, snapshot_frequency를 조정해 워크로드 특성에 맞게 재개 지연 시간과 저장 효율 사이를 트레이드오프 할 수 있습니다. K를 더 크게 잡으면 세션당 전체 스냅샷 횟수가 줄어들어 저장 효율은 높아지지만, 재개 시에 재생해야 하는 delta 수가 약간 늘어납니다.
워크로드 B: 멀티 파일 코딩 세션
턴당 상태가 더 무거운 시나리오에서는 O(N²) 곡선이 훨씬 더 가파르게 상승합니다. 기준 방식은 겨우 200턴 만에 5.3GB에 도달하는데, 이는 현실적인 “하루 오후 내내 에이전트를 돌린” 정도의 작업량입니다.
이 워크로드에서 절감 비율은 200턴 시점에 41배에 도달해 있고, 여전히 상승 중입니다. 두 워크로드 모두 이론적인 상한(~K배)으로 수렴하지만, 턴당 상태가 더 큰 워크로드 B가 O(N²) 계수를 더 빠르게 키우기 때문에 상한치에 더 빨리 근접합니다.
각 턴 수 지점에서 워크로드 B의 절감 비율이 항상 더 높은 것도 같은 이유입니다. 턴당 상태 크기가 클수록 O(N²) 계수가 더 빨리 커지고, 그만큼 delta 방식이 가져오는 절대 절감 폭도 커집니다. 결국 두 워크로드 모두 비슷한 상한(~snapshot_frequency배)에 수렴하지만, 무거운 워크로드일수록 그 지점에 더 빨리 도달하는 셈입니다.
API
Deep Agents에서
deepagents v0.6에서는 Delta 채널이 기본으로 활성화되어 있습니다. messages와 files 모두 delta 채널에 의해 관리됩니다. 별도의 설정은 필요 없습니다.
LangGraph에서
DeltaChannel은 LangGraph에서 어떤 상태 필드에도 사용할 수 있는 일급(First-class) 프리미티브입니다.
from typing_extensions import Annotated
from langgraph.channels.delta import DeltaChannel
def append(state: list[str], writes: list[list[str]]) -> list[str]:
return state + [item for batch in writes for item in batch]
class MyAgentState(TypedDict):
items: Annotated[list[str], DeltaChannel(reducer=append, snapshot_frequency=50)]파라미터는 두 가지입니다.
-
reducer— 순수 함수(state, list[writes]) ->; new_state로, 배치 단위에 상관없이 항상 같은 결과를 내야 합니다. 즉,reducer(reducer(s, xs), ys) == reducer(s, xs + ys) 를 만족해야 합니다. 아래에서 설명하는 reducer 계약을 참고하세요. -
snapshot_frequency— 전체 스냅샷을 얼마나 자주 쓸지(기본값: 1000). 이 값을 키우면 세션당 전체 스냅샷 횟수가 줄어 저장 효율은 좋아지지만, 재개 시 재생해야 하는 delta가 많아집니다. deepagents에서는 50을 사용합니다.
위가 API 변경 사항의 전부입니다. 기존 툴, 인터럽트 처리, 타임 트래블 기능은 그대로 동작합니다.
리듀서 계약: fold 전반에서의 결합성(associativity)
DeltaChannel은 예전 BinaryOperatorAggregate 채널보다 더 엄격한 리듀서 조건을 요구합니다. delta 기반 상태를 직접 정의할 때 반드시 올바르게 맞춰야 하는 부분입니다.
이전 계약
def reducer(existing: T, update: T) -> T: …새로운 계약
# Batch fold — called with ALL accumulated writes at once
def reducer(state: T, writes: list[T]) -> T: …DeltaChannel은 마지막 로드(load) 이후 누적된 모든 write를 한 번에 리스트로 넘겨 줍니다. 이때, write가 어떠한 배치 단위로 나뉘어서 처리되더라도 최종 결과는 항상 동일해야 합니다.
reducer(reducer(state, [w1, w2]), [w3, w4]) == reducer(state, [w1, w2, w3, w4])이를 **batching-invariance(배치 불변성)**라고 부릅니다. 이 조건을 어기면, delta 채널로 복원한 상태와 전체 스냅샷 기반 상태가 스냅샷 경계를 넘는 긴 세션에서만 은밀하게 서로 어긋나게 됩니다.
기존(프리-delta) 스레드 마이그레이션
별도 데이터 마이그레이션은 필요 없습니다. DeltaChannel.from_checkpoint가 일반 상태 값( _DeltaSnapshot 이 아닌 값)을 만나면, 그 값을 그대로 기본 상태(base state)로 사용합니다. 기존 스레드는 그대로 동작하며, 업그레이드 후 처음 생성되는 새 체크포인트부터 그 plain 값 위에 delta가 쌓이기 시작합니다.
앞으로의 계획
Delta 채널은 deepagents v0.6 및 langgraph v1.2에 포함되어 있습니다. 업그레이드 경로는 최대한 매끄럽게 설계했습니다.
세션이 길어질수록 Delta 채널이 가져오는 이점은 더 커집니다. 깊은 컨텍스트를 가진 장시간 실행 에이전트는 이 분야가 나아가는 방향이고, Delta 채널은 바로 이런 에이전트를 무리 없이 운영할 수 있도록 런타임을 확장하는 핵심 메커니즘입니다.